Prompt engineering——吴恩达课程笔记
最近,吴恩达在 deeplearning.ai 平台上发布了一门关于 LLM 提示工程的课程。
课程很简短,只有 9 集,时长一个半小时,B 站上有中文字幕:【中文完整版全9集】ChatGPT提示工程。
不过还是推荐利用 deeplearning 平台提供的 jupyter notebook 实战一下:
本文简单做个总结,以供日后查询。
前言:RLHF
大语言模型(LLM)在语料库上训练之后,并不能达到如 ChatGPT 那般令人惊艳的效果。本质上 LLM 的能力就是给定一段文字,进行续写。举个例子:给它一段文字 What is the capital of France?,LLM 可能会续写 What is the largest city in France?。这个续写是符合逻辑的,但却不是我们想要的——它并没有回答问题。 我们把这个阶段叫做 Base LLM
要让 LLM 显得更加智能,以人类能接受的方式生成回答,ChatGPT 用到了 RLHF (Reinforcement learning with human feedback) 的技术。经过 RLHF 微调的模型,我们叫做 Instruction Tuned LLM
注 1:最早把强化学习引入语言模型中的,是 OpenAI 在 2019 年的一篇工作:Fine-Tuning Language Models from Human Preferences
注 2:RLHF 并不能有效提升模型的跑分,在小模型上性能甚至会有比较大的下降(随着参数增多,RLHF 微调会稍微增强性能),但是可以让它“显得”更智能
InstructGPT (arxiv.org) 中详细介绍了 RLHF:
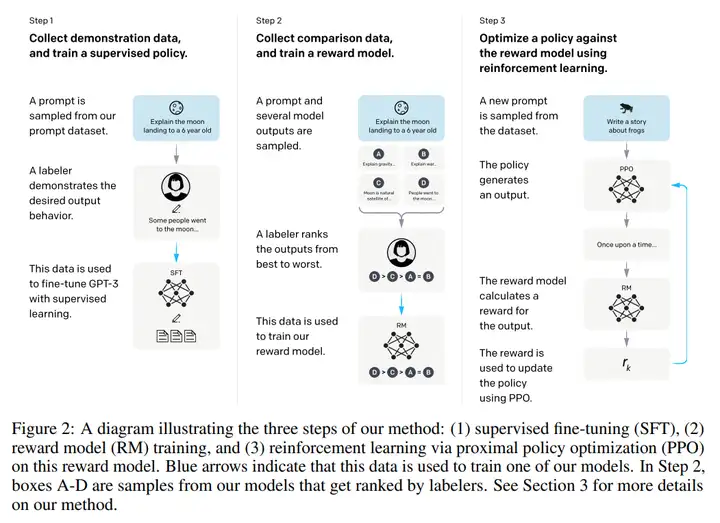
整个过程可以分成三步:
首先,通过人工写回答,收集了一个 prompt-response 数据集,用它对 GPT3 作微调,教会它如何产生人类想要的回答,得到的模型记作 fine-tuned GPT3。
第二步,利用 fine-tuned GPT3 对某个 prompt 产生多个回答,并人工对它们按照好坏进行排序,可以称作 ranking 数据集。借助这些数据,训练一个 reward model,用来评估 response 的好坏,训练目标是尽量接近于人工排序。
第三步,利用强化学习 PPO 算法,对 fine-tuned GPT3 进行优化。用强化学习中的术语来说, fine-tuned GPT3 就是 agent;Reward model 就是 environment,为 agent 的回答提供反馈。Agent 利用这个反馈优化自身参数,继续与环境交互,从而迭代优化。
以上三步就是 InstructGPT 相对于 GPT3 所做的优化。
Note:相比于第二步中的 ranking 数据集,第一步中 prompt-response 数据集的收集代价更为昂贵(排序比自己写答案要简单太多了)。其实如果 prompt-response 数据集足够大,可以只用它在 GPT3 上做微调,而不需要强化学习。
Note:1.3B(13亿)参数量的 InstructGPT 产生的回答,效果要好于 175B 的 GPT-3
与 InstructGPT 同一时期的、Anthropic 的一篇工作 Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback 中提到:
We expect human feedback (HF) to have the largest comparative advantage over other techniques when people have complex intuitions that are easy to elicit but difficult to formalize and automate
也就是说,当一些复杂的任务涉及到人类的直觉,没有显性的公式作为优化目标时,我们希望 RLHF 能解决这一问题。
提示工程的两大原则
首先来个全文简洁版:1. 给出清晰和明确的指令(Write clear and specific instructions)
- 使用分隔符清晰地将Prompt输入的不同部分分开
- 要求结构化的输出,如输出为json、html、xml等格式
- 检查内容是否满足任务所需的条件,拒绝无效或非法的内容
- 给出几个任务的示例(Few-shot)2. 给模型一些思考的时间(Give the model time to think)
- 给模型一些思考的时间
- 指导模型在得出结论之前先自行解决问题具体内容继续往下看
Write clear and specific instructions
技巧一:使用分隔符可以使用各种各样的分隔符,将特殊的指令单独分隔开:
Triple quotes
"""
Triple backticks```
Triple dashes---
Angle brackets< >
XML tags<tag> </tag>举个例子:
text = f"""
A long text...
"""
prompt = f"""
Summarize the text delimited by triple backticks \
into a single sentence.
```{text}```
"""
技巧二:获取结构化的输出可以要求模型以 JSON、字典或者其他格式输出结果:
prompt = f"""
Generate a list of three made-up book titles along \
with their authors and genres.
Provide them in JSON format with the following keys:
book_id, title, author, genre.
"""
技巧三:让 LLM 检查文本是否满足条件下面的例子中,如果给定的文本包含一系列指令,就让 LLM 以特定格式列出来;否则,就输出 No steps provided.
prompt = f"""
You will be provided with text delimited by triple quotes.
If it contains a sequence of instructions, \
re-write those instructions in the following format:
Step 1 - ...
Step 2 - …
…
Step N - …
If the text does not contain a sequence of instructions, \
then simply write \"No steps provided.\"
\"\"\"{text_1}\"\"\"
"""Note: \ 是转义符; " 代表引号
技巧四:Few-shot prompting所谓 Few-shot,就是为模型提供几个问答的例子,让 LLM 熟悉这种风格,并按此产生回答。
Give the model time to think
技巧一:明确完成任务所需的步骤
下面的例子里,将任务分成了若干部分,让 LLM 分别完成
prompt_1 = f"""
Your task is to perform the following actions:
1 - Summarize the following text delimited by triple \
backticks with 1 sentence.
2 - Translate the summary into French.
3 - List each name in the French summary.
4 - Output a json object that contains the following \
keys: french_summary, num_names.
Separate your answers with line breaks.
Text:
```{text}```
"""利用原则一中的技巧二,获取结构化的输出:
prompt_2 = f"""
Your task is to perform the following actions:
1 - Summarize the following text delimited by triple \
backticks with 1 sentence.
2 - Translate the summary into French.
3 - List each name in the French summary.
4 - Output a json object that contains the following \
keys: french_summary, num_names.
Use the following format:
Text: <text to summarize>
Summary: <summary>
Translation: <summary translation>
Names: <list of names in French summary>
Output JSON: <json with summary and num_names>
Text:
```{text}```
"""
LLM 的具体功能
上面给出了提示工程的总体原则。下面来看看,针对各种具体需求的 prompt 模板。
不过在此之前,有几点要注意:
- 这门课程中,我们使用反斜杠 \ 来使一行文本不至于过长,而不用换行符 \n。
- 无论是否插入换行符,GPT3 其实都不会受到影响。但在一般情况下需要考虑在提示中的换行符是否会影响 LLM 的性能。
- 温度 (Temperature) 是 LLM 的一个超参数,可以视作 LLM 的探索自由度或随机性。温度越高,探索自由度越高。
- 温度为 0 时,给定相同的输入和提示,生成的结果总是一样的。当我们想保证可复现性时,应该设置温度为 0;如果要获得更多样性的输出,每次都有新感觉,应该设置更高的温度。
总结 Summarizing
对目标文本进行总结归纳:
prompt = f"""
Your task is to generate a short summary of a product \
review from an ecommerce site to give feedback to the \
Shipping department.
Summarize the review below, delimited by triple
backticks, in at most 30 words, and focusing on any aspects \
that mention shipping and delivery of the product.
Review: ```{prod_review}```
"""☝️☝️☝️
上面的 prompt 要求 LLM 做一个总结:它给出了待总结文字的特征 (指明它是一段
product review) 和来源 (来自ecommerce site);并且限制了总结的长度 (at most 30 words);明确了需要侧重的方面 (any aspects that mention shipping and delivery of the product)另外,可以只提取信息,而非总结。这样可以更加突出要点,只保留关注的信息:
prompt = f"""
Your task is to extract relevant information from \
a product review from an ecommerce site to give \
feedback to the Shipping department.
From the review below, delimited by triple quotes, \
extract the information relevant to shipping and \
delivery. Limit to 30 words.
Review: ```{prod_review}```
"""
推理 Inferring
从给定文字中推理主题以及情感态度(积极或消极)
态度推理:
prompt = f"""
What is the sentiment of the following product review,
which is delimited with triple backticks?
Give your answer as a single word, either "positive" \
or "negative".
Review text: '''{lamp_review}'''
"""情感推理:
prompt = f"""
Identify a list of emotions that the writer of the \
following review is expressing. Include no more than \
five items in the list. Format your answer as a list of \
lower-case words separated by commas.
Review text: '''{lamp_review}'''
"""主题推理:
prompt = f"""
Determine five topics that are being discussed in the \
following text, which is delimited by triple backticks.
Make each item one or two words long.
Format your response as a list of items separated by commas.
Text sample: '''{story}'''
"""
转换 Transforming
文本转换任务,包括但不限于语言翻译、拼写和语法检查、语气调整和格式转换(例如 HTML 到 JSON)
ChatGPT 的训练语料库包含各种语言,翻译自然不在话下:
prompt = f"""
Translate the following text to Spanish in both the \
formal and informal forms:
'Would you like to order a pillow?'
"""语气转换,比如从对话体转变成邮件体:
prompt = f"""
Translate the following from slang to a business letter:
'Dude, This is Joe, check out this spec on this standing lamp.'
"""格式转换,利用得当可以省掉正则表达式的繁重工作。一个 JSON 格式到 HTML 的例子:
data_json = { "resturant employees" :[
{"name":"Shyam", "email":"shyamjaiswal@gmail.com"},
{"name":"Bob", "email":"bob32@gmail.com"},
{"name":"Jai", "email":"jai87@gmail.com"}
]}
prompt = f"""
Translate the following python dictionary from JSON to an HTML \
table with column headers and title: {data_json}
"""语法检查:在发邮件、写文章时,用 ChatGPT 进行语法检查,多是一件美事啊
prompt = f"""
Proofread and correct the following text. If you don't find
and errors, just say "No errors found". Don't use
any punctuation around the text:
```{text}```
"""
扩展 Expanding
将短文本(如一组关键词或者主题)扩展为更长的文本(如邮件或者一封主题相关的文章)
例子:根据用户的评论,让 LLM 作为客服写回复邮件
prompt = f"""
You are a customer service AI assistant.
Your task is to send an email reply to a valued customer.
Given the customer email delimited by ```, \
Generate a reply to thank the customer for their review.
If the sentiment is positive or neutral, thank them for \
their review.
If the sentiment is negative, apologize and suggest that \
they can reach out to customer service.
Make sure to use specific details from the review.
Write in a concise and professional tone.
Sign the email as `AI customer agent`.
Customer review: ```{review}```
Review sentiment: {sentiment}
"""这里的
sentiment可以不给定,可以让 LLM 自动从评论中推理情感。注:Sign the email as
AI customer agent很重要。创作文章或邮件时,注明 AI 创作是必须的。
搭建聊天机器人
OpenAI 提供的 ChatGPT API openai.ChatCompletion 用到的 messages 格式是一个字典的列表,每一个字典包括 role: content 的键值对。
其中 content 就是信息字符串。role 是说话的角色,可以分为三种:system, user, assistant。其中 system 相当于为聊天机器人设置的出厂设置,为它设定规则和背景;user 是用户发送的信息;assistant 是机器人的回复。我们在 ChatGPT Web 页面聊天框输入的信息,属于 user 信息;得到的回复属于 assistant 信息。
例如:
messages = [
{'role':'system', 'content':'You are an assistant that speaks like Shakespeare.'},
{'role':'user', 'content':'tell me a joke'},
{'role':'assistant', 'content':'Why did the chicken cross the road'},
{'role':'user', 'content':'I don\'t know'} ]这里给出了一个披萨点单机器人的 demo:
首先设置
system message,给出背景场景,指明机器人要做的事,并在每一步细化要求(如外卖时要询问用户地址)。我们还规定了机器人回复的长度和语气,给出了菜单信息。context = [ {'role':'system', 'content':"""
You are OrderBot, an automated service to collect orders for a pizza restaurant. \
You first greet the customer, then collects the order, \
and then asks if it's a pickup or delivery. \
You wait to collect the entire order, then summarize it and check for a final \
time if the customer wants to add anything else. \
If it's a delivery, you ask for an address. \
Finally you collect the payment.\
Make sure to clarify all options, extras and sizes to uniquely \
identify the item from the menu.\
You respond in a short, very conversational friendly style. \
The menu includes \
pepperoni pizza 12.95, 10.00, 7.00 \
cheese pizza 10.95, 9.25, 6.50 \
eggplant pizza 11.95, 9.75, 6.75 \
fries 4.50, 3.50 \
greek salad 7.25 \
Toppings: \
extra cheese 2.00, \
mushrooms 1.50 \
sausage 3.00 \
canadian bacon 3.50 \
AI sauce 1.50 \
peppers 1.00 \
Drinks: \
coke 3.00, 2.00, 1.00 \
sprite 3.00, 2.00, 1.00 \
bottled water 5.00 \
"""} ] # accumulate messages然后写一个收集信息、调用 API 的函数。它每次把用户的输入信息和机器人回复信息加入到 context 列表中,作为后面对话的背景信息。
def collect_messages(_):
prompt = inp.value_input
inp.value = ''
context.append({'role':'user', 'content':f"{prompt}"})
response = get_completion_from_messages(context)
context.append({'role':'assistant', 'content':f"{response}"})
panels.append(
pn.Row('User:', pn.pane.Markdown(prompt, width=600)))
panels.append(
pn.Row('Assistant:', pn.pane.Markdown(response, width=600, style={'background-color': '#F6F6F6'})))
return pn.Column(*panels)然后调用它:
import panel as pn # GUI
pn.extension()
panels = [] # collect display
inp = pn.widgets.TextInput(value="Hi", placeholder='Enter text here…')
button_conversation = pn.widgets.Button(name="Chat!")
interactive_conversation = pn.bind(collect_messages, button_conversation)
dashboard = pn.Column(
inp,
pn.Row(button_conversation),
pn.panel(interactive_conversation, loading_indicator=True, height=300),
)
dashboard
此时就可以展开对话了。
LLM 的局限性
LLM 一个被广泛讨论的局限性,就是它有时会一本正经且十分自信地胡说八道。
解决方法:LLM 给出回答的同时,给出引用的文献和资料。然后我们可以根据这些引用去验证回答的真实性。
提示工程的迭代优化
机器学习里,要先有一个能跑通的模型,才能对它进行改进;提示工程也一样,最初版本的 prompt 或许不够完美,我们要学会如何一步步细化要求,进行迭代改进。
比如限制输出的长度:Use at most 50 words.
再比如明确目标受众,更明确地聚焦于某个方面:The description is intended for furniture retailers, so should be technical in nature and focus on the materials the product is constructed from.
还有就是像上面说的那样,让输出结果更加结构化,以 JSON 或者表格的格式输出,甚至可以要求以 HTML 代码的格式输出:Format everything as HTML that can be used in a website. Place the description in a <div> element.
总之,编写 prompt 的思路就是先有一个简单的版本,然后在迭代中优化!
补遗
OpenAI examples 给出了许多任务的 Prompt 示例,如 Q&A,summarization,还有 Python bug fixer, SQL request 等等。大家可以去探索一番。
(转载知乎笔记:暖暖内含光)


